.png.webp)
모요 데이터 이야기 : 데이터 파이프라인 구축하기
모요의 핵심가치 중 가장 강조되는 핵심 가치 중 하나가 “데이터 기반 사고“ 인데요. 그래서 모요의 데이터 챕터는 모요가 핵심가치에 맞게 일 할 수 있도록 모두가 데이터를 보거나 분석하기 쉬운 문화를 만드려 노력해 왔어요.
지금부터 저희가 데이터 파이프라인을 만들어온 이야기를 들려드릴게요.
기존 파이프라인과 문제점
기존 AWS 파이프라인
.png.webp)
모요 기존 데이터 파이프라인
기존 파이프라인은 아래와 같이 구성했었어요.
- 서비스 데이터, 외부 데이터: AWS lambda와 Event Bridge를 이용하여 S3에 parquet로 적재
- 로그 데이터
- 로그서버에서 믹스패널에 로그 발송
- 로그 서버 → SQS → Firehose → S3에 parquet로 적재
- 모든 데이터는 아테나를 통해서 조회
이 파이프라인은 2022년 6월부터 활용하여 현재 2년간 활용 되고 있었어요.
뭐가 문제 였을까요?
.png.webp)
1. 리소스는 없는데 관리하기가 어려웠어요.
- 회사가 너무 빠르게 일하다 보니 일일이 컬럼이나 테이블 추가를 따라가기 어려웠어요.
- 기존 파이프라인에서는 람다에서 테이블이나 컬럼을 코드로 추가해야 함
- 그래서 테이블이나 컬럼추가시 람다에 변경된 코드를 배포해서 처리해줘야 함
- 파이프라인에 장애가 났을 때 Dependency 관리가 어려웠어요.
- 데이터 파이프라인 구조가 데이터 덤프 람다 → 마트 람다 구조였음
- 해당 파이프라인이 명확하게 DAG처럼 도식화해서 관리가 되지 않았었음
아테나를 활용하고 싶은 동료들에게 계속 AWS 계정을 발급해야 했어요.
- 데이터 접근에 대한 권한관리도 어려운 상황
2. 데이터 용량이 커지다보니 Lambda로 처리하기 어려운 데이터들이 생겼어요.
- 람다에서 처리할수 있는 메모리 용량이 최대 10기가 정도인데,
- 그 이상에 데이터를 처리해서 마트로 만들어야 하는 상황이 생겼어요.
3. 데이터 엔지니어가 없다보니 개선이나 관리를 맡아서 Fully 일 할 수 있는 사람이 없었어요.
- 계속 개선하고 싶지만 회사에 데이터 인력은 분석가만 2명인 상황이었고,
- 관련해서 도와주시는 backend도 한 분 계시지만 절대적인 리소스가 부족했죠.
현재의 파이프라인
.png.webp)
모요의 현재 파이프라인
왜 GCP였는가?
위의 문제점들을 요약하면 아래와 같아요.
“현재 파이프라인에서 배치를 처리하는 친구들의 성능이 좋지않다.”
“관리가 어렵다.”
“근데 관리할 리소스는 없다.”
이런 문제가 대두되면서 저희 팀 내부에서 고민이 생겼었던것 같아요.
“최대한 관리가 편한 시스템을 선택하여 최대한 자동화 해야하는 걸까?“
고민하던 중에 그냥 관리가 편해보이는(?) GCP 시스템을 도입해보자는 선택을 하게 됐어요.
(개인적으로 저한테 좀 편했던 것 같아요. + 덤으로 크레딧이 있어서 쓰고 싶었어요!)
“성능이 좋지않다.” 부터 해결해보자
.png.webp)
성능 좋은 Google BigQuery를 쓸 거예요.
- 일단, 현재 활용하는 AWS Athena 보다 Google BigQuery가 성능 면에서 확실히 더 좋아요.
- 배치 차원에서도 AWS Lambda + AWS Athena 조합으로 요구사항을 다 처리하기가 어려웠어요. 그래서 자연스럽게 GCP 에서 Composer + BigQuery Operator를 생각하게 됐죠.
- 쿼리 성능 이외에도 Google BigQuery를 이용하는게 모요 조직에 적합하다고 판단했어요.
- 분석 시, 반복되는 SQL이 많아서 UDF를 활용하고 싶었음. (AWS Athena에서 UDF도 만들 수 있긴하지만 Google BigQuery가 훨씬 간단함)
- Airflow를 활용해서 마트 Job을 할때는 BigQuery Operator를 써서 처리하는게 EMR 인스턴스를 띄워서 처리하는 것 보다 관리차원에서 쉬움.
- 대부분 분석 내용을 스프레드 시트로 복사해서 공유하는 경우가 많은데 이 경우도 Google BigQuery와 연동되서 지원되는게 많음.
“관리가 어렵다.” 도 해결해보자
여기서의 관리에 대한 문제는 여러가지가 있었고 하나씩 해결했어요.
1. Data Lake 테이블, 컬럼 추가 및 관리의 어려움 : DataStream을 통한 테이블과 컬럼 자동 동기화
- DataStream은 구글 소개를 빌려보자면 사용하기 쉬운 서버리스 변경 데이터 캡처(CDC) 및 복제 서비스로서 최소한의 지연 시간으로 데이터를 안정적으로 동기화할 수 있게 해주는 서비스예요.
- 쉽게 말해서 RDS에서 데이터가 insert, update, delete 되는 경우이거나, 테이블이 추가되는 경우 그 변경사항을 특정시간이 지나면 빅쿼리로 동기화 해주는 서비스인 거죠.
- 서비스 레플리카 RDS에 DataStream을 붙여서 빅쿼리와 동기화하도록 만들었어요.
.png.webp)
동기화된 모습
2. Job별 Dependency 관리의 어려움 : Cloud Composer로 Job orchestration
- 기존의 Lambda to Lambda 구조에서는 의존관계를 파악하기 어렵고, 오류가 발생했때 복구도 쉽지 않았어요.

(과거) 데이터 배치 람다
데이터 마트 람다
- 현재는 Cloud Composer(airflow)에서 의존성을 관리할 수 있고, Cloud Composer에서 BigQuery Operator들을 활용하여 쉽게 연산할 수 있어요.

(현재) Cloud Composer(airflow)에서 의존성 관리
3. 로그 전송구조의 복잡성: pub/sub to BigQuery로 간소화
- 로그 발송용 pub/sub가 SNS + SQS + Firehose 같은 역할을 해줘요.
- 큐 + 데드레터큐 + Google BigQuery를 통해 스키마에 맞게 전송해요.
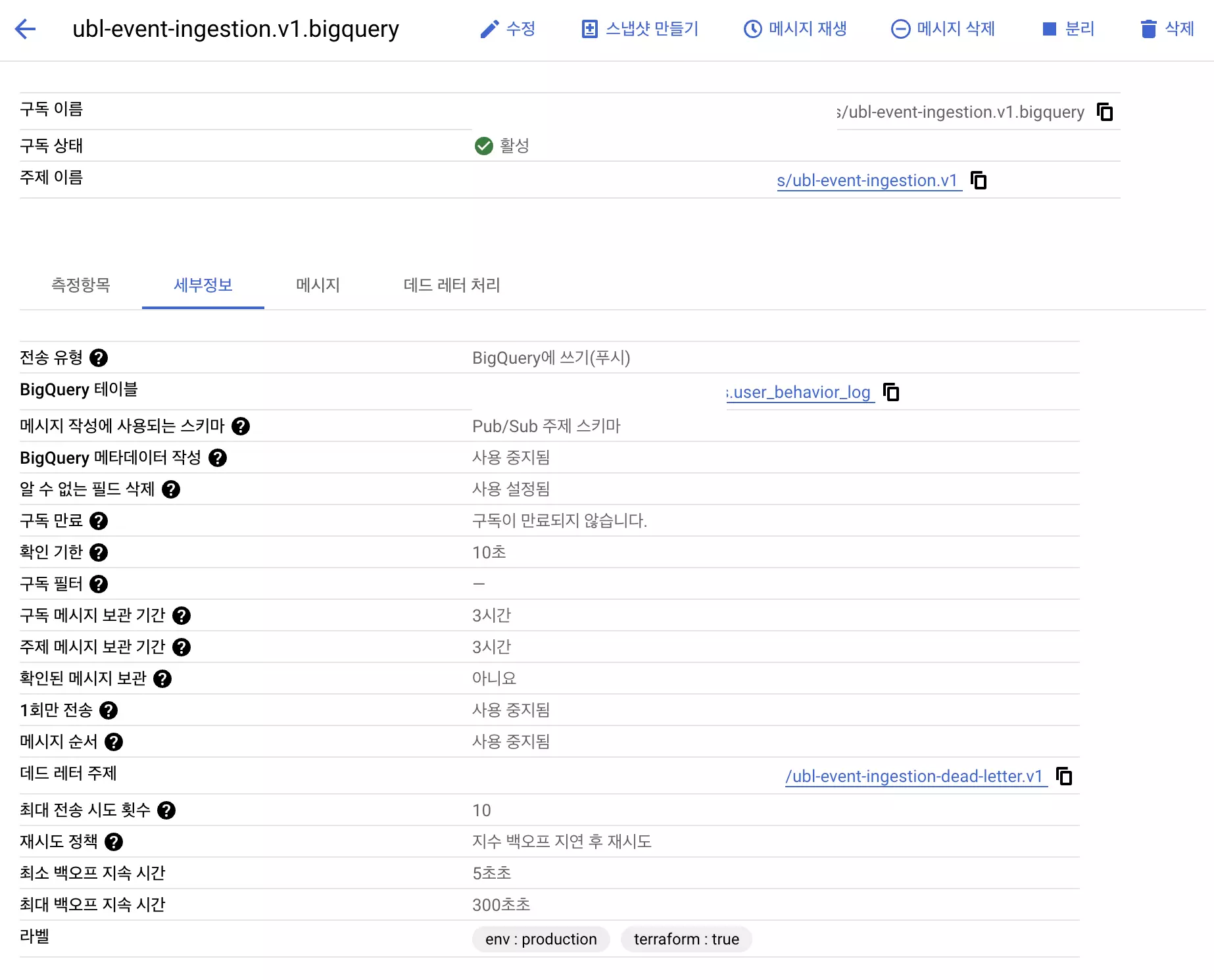
파티션이나 테이블 관리 정책은 빅쿼리에서 정해요.
.png.webp)
결과로 받게되는 빅쿼리 테이블
4. 계정 관리가 어려움: Google Workspace활용
- Google Workspace를 활용해서 업무를 하고 구글 계정과 BigQuery계정을 연동해 활용할 수 있어요.
- GCP 프로젝트 단위로 쪼개서 권한을 관리해요.
그리고 앞으로...
이런 과정을 통해서 기존의 파이프라인이 가지고 있던 문제들을 많이 해소할 수 있었어요. 사실 아직 마이그레이션이 조금 남아있긴 하지만, 내부 동료들도 만족스럽게 Google BigQuery를 활용하고 있어요.
.png.webp)
그러나 데이터 파이프라인이 개선되었다고 해서 모든 것이 해결된 건 아니에요. 데이터 품질 관리나 데이터 카탈로그, 데이터 거버넌스 수립 등등 많은 일들이 남았어요. 앞으로 GCP기반의 데이터 환경에서 동료들이 데이터를 더 잘 활용할 수 있도록 여러가지 노력을 할 예정이에요.
더 궁금한 부분이 있으시면, 커피챗을 신청해주세요. 자세한 건 커피챗을 통해서 알려 드릴게요.